This discussion on HN about why you may not need anything other than Postgres: https://news.ycombinator.com/item?id=42036303
brings up a good question about Redis- one I've wondered myself: Are we using Redis the wrong way?
The main use of Redis is as a simple key/value store. The idea is that if we are doing a process such as a DB query, we can cache the result. This is essentially memoization, and I remember this being used way back with a program called memcached.
Redis is a highly optimized key/value store, but many people (myself included) use hosted Redis servers. This introduces a lot of overhead on reads.
Wouldn't we be better off moving the key/value pair server as close to the application as possible, and then relying on writes being distributes to all instances? At worst we might get old data, but if we're using the system for caching, that shouldn't matter much, and we can instead rely on eventual consistency.
I'm curious as to other's thoughts on this.
#Redis
#KeyDB
#SystemArchitecture









 Software design is critical for building scalable, maintainable, and efficient systems.
Software design is critical for building scalable, maintainable, and efficient systems.
 Scalable architectures, two concepts: 𝙎𝙘𝙖𝙡𝙚-𝙐𝙥 𝙖𝙣𝙙 𝙎𝙘𝙖𝙡𝙚-𝙊𝙪𝙩
Scalable architectures, two concepts: 𝙎𝙘𝙖𝙡𝙚-𝙐𝙥 𝙖𝙣𝙙 𝙎𝙘𝙖𝙡𝙚-𝙊𝙪𝙩
 Link to the full blog post:
Link to the full blog post: 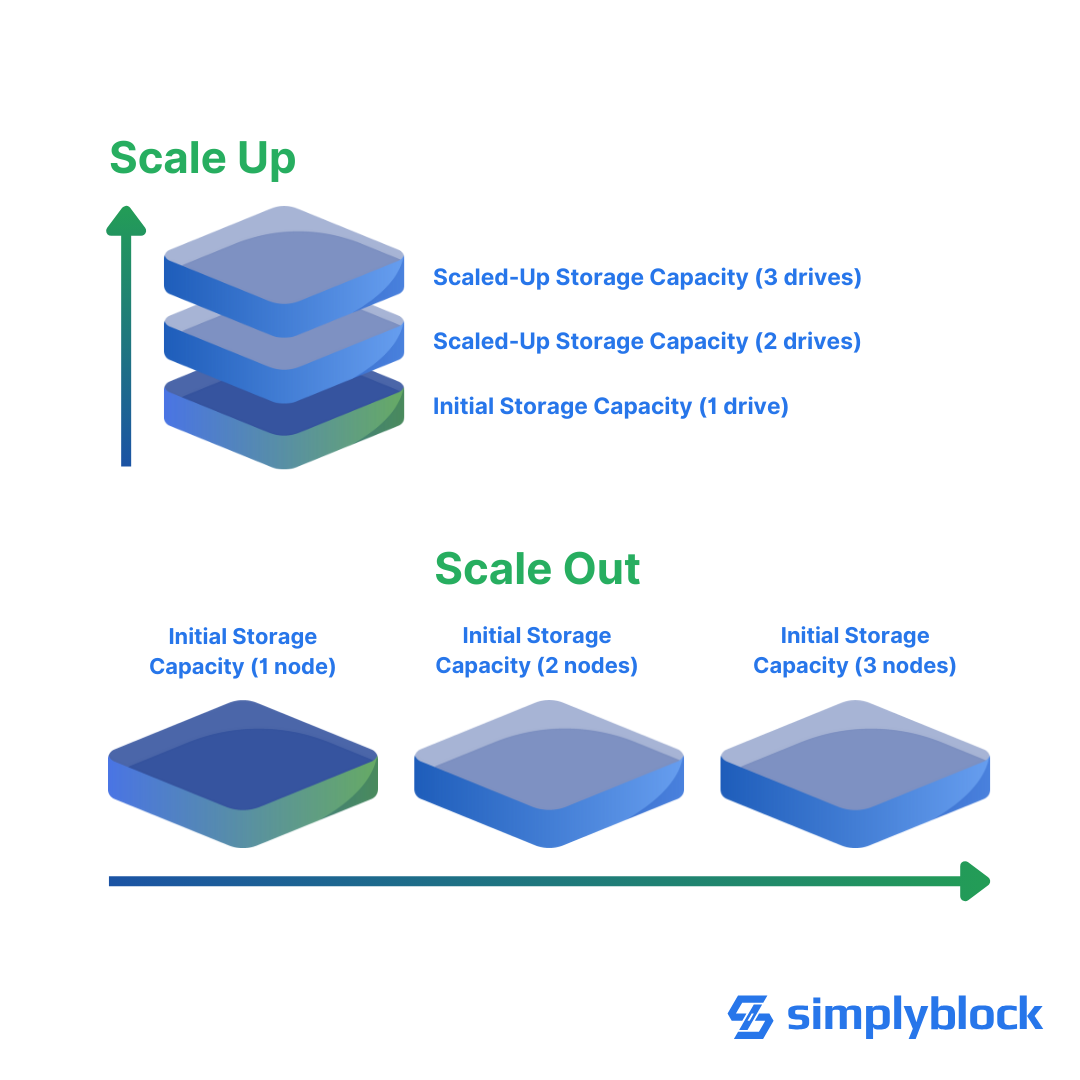



 .
. 



 (seasonally appropriate remix)
(seasonally appropriate remix) 